How We Thought of Our In-House SLM Distillation Platform
Last year I was building a conversational AI agent for a fintech company. The agent handled loan origination workflows, KYC verification, and customer support. The kind of work where getting things wrong has regulatory consequences. We picked GPT-4.1 as our backbone. In development, it was flawless. Accurate reasoning, proper citations, never hallucinated on compliance-sensitive prompts.
Then we went to production.
At 5-10k sessions per day, each averaging around 20 turns of back-and-forth, the inference bill crossed $52K/month. P95 response latency sat around 3.2 seconds, which is brutal for a conversational agent where users expect sub-second replies. We were burning money and frustrating users simultaneously.
The obvious fix was: “just use a smaller model.” So we tried. Swapped GPT-4.1 for an off-the-shelf 7B parameter model. Quality collapsed immediately. The model missed regulatory edge cases, generated vague responses where precision was required, and broke on multi-step compliance reasoning. We rolled back within a day.
That failure forced a question that shaped everything we built next: how do you get frontier-model quality at small-model prices, specifically for your use case?
Why “Just Use a Smaller Model” Doesn’t Work
The quality gap between frontier models (GPT-4.1, Claude) and small open-source models (Llama 7B, Mistral 7B) is well-documented on general benchmarks. But on domain-specific tasks like financial compliance language, regulatory edge cases, nuanced KYC reasoning, the gap is even wider.
Here is the thing though: small models are not universally bad. They are bad at things they have never been specifically taught. A 7B model has plenty of capacity to handle loan origination conversations. It just lacks the specific knowledge and behavioral patterns that our application demands.
# The problem in a nutshell
teacher_response = frontier_model.generate(
"Evaluate this loan application against Reg B and ECOA requirements. "
"The applicant has a thin credit file with 2 tradelines..."
)
# Result: Detailed analysis citing specific regulatory clauses,
# identifies the thin-file as a potential fair lending concern,
# recommends specific documentation steps
student_response = small_model.generate(
"Evaluate this loan application against Reg B and ECOA requirements. "
"The applicant has a thin credit file with 2 tradelines..."
)
# Result: "The loan application should be reviewed for compliance
# with relevant regulations." - useless.
This gap is not about raw intelligence. It is about training distribution. The small model has seen regulatory text during pretraining, but never in the context of making actual lending decisions. It does not know what a correct answer looks like for our use case.
That realisation led to an insight drawn from classical ML: knowledge distillation (Hinton et al., 2015). What if we could teach a small model to behave exactly like the frontier model, but only for the narrow distribution of tasks our agent actually handles?
The Teacher-Student Architecture
We designed a system with two model roles:
Teacher Model: The larger, more capable model. In our case, GPT-4.1 with 180B+ parameters. It serves as the quality benchmark. Whatever the teacher produces for our use case is the gold standard. Its outputs are expensive, but they define what “correct” looks like.
Student Model: A smaller, cost-optimised model. We started with Llama 3.1 8B. The student gets trained to replicate the teacher’s behavior specifically on our application’s conversation patterns. It does not need to be generally intelligent. It needs to be specifically excellent at the narrow distribution of tasks our agent handles.
The critical distinction from generic fine-tuning: we are not training on public datasets or synthetic benchmarks. We are training on the teacher’s actual outputs from real production conversations. The student learns not just what to say, but how the teacher reasons about our specific domain — the formatting conventions, the tool call patterns, the regulatory citation style.
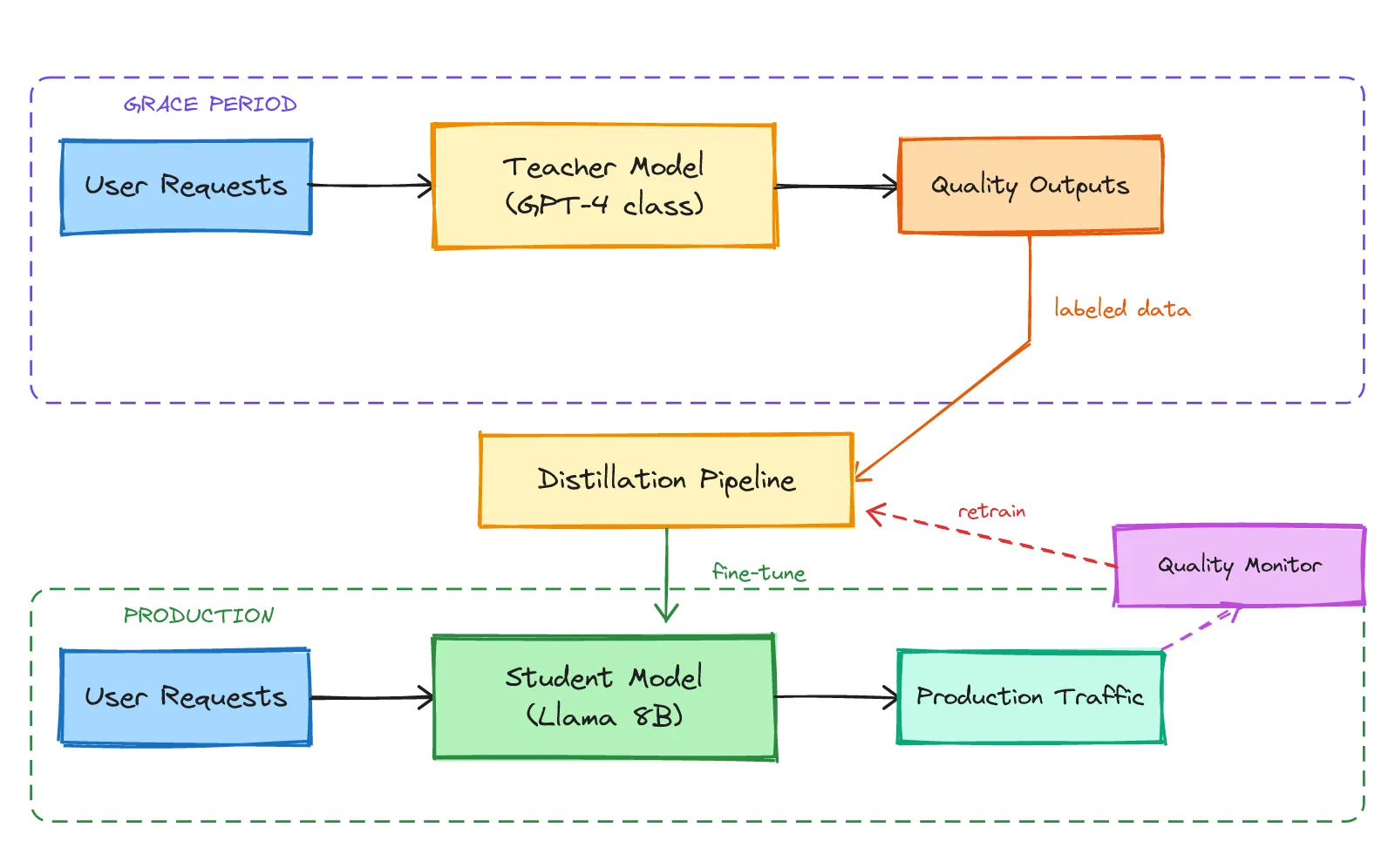
The architecture has a natural feedback loop. Users send requests. During the initial phase, the teacher handles them all and produces high-quality outputs. Those outputs feed into a distillation pipeline that trains the student. Once trained, the student handles production traffic at a fraction of the cost. A quality monitor continuously compares student outputs against what the teacher would have produced, triggering retraining if quality drifts.
Designing the Model Tiers
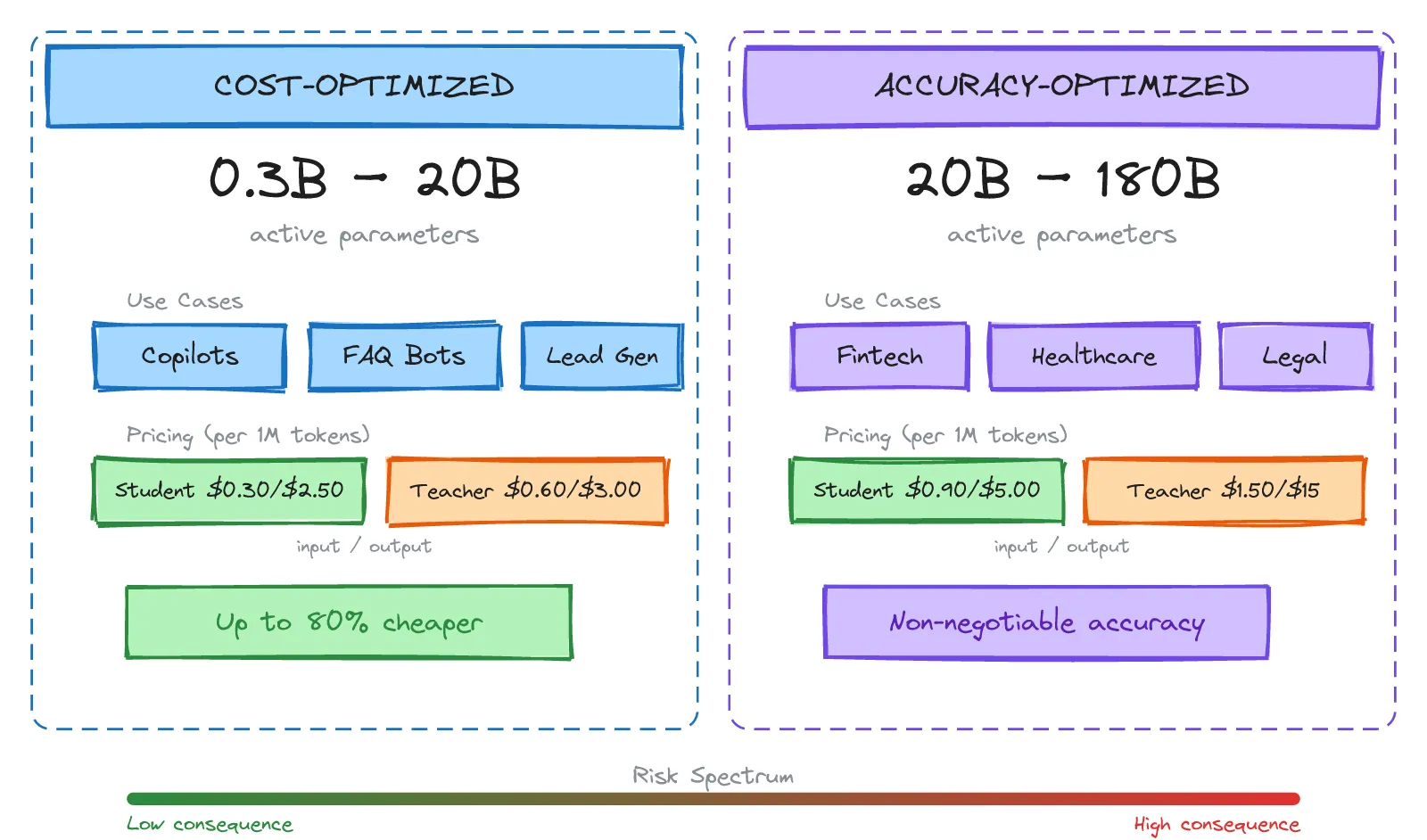
Not all use cases have the same quality requirements. We quickly realised we needed two distinct tiers, differentiated by consequence of failure.
Cost-Optimised Tier (0.3B to 20B active parameters): Built for high-volume, lower-stakes interactions. FAQ bots, AI copilots, lead generation agents, internal tools. Accuracy matters, but an occasional imperfection will not trigger a regulatory audit.
- Student: ~$0.30 input / $2.50 output per 1M tokens
- Teacher: ~$0.60 input / $3.00 output per 1M tokens
Accuracy-Optimised Tier (20B to 180B active parameters): Built for compliance-sensitive, high-stakes domains. Financial services, healthcare documentation, legal review. Errors here have regulatory consequences. These models handle greater nuance and multi-step reasoning.
- Student: ~$0.90 input / $5.00 output per 1M tokens
- Teacher: ~$1.50 input / $15.00 output per 1M tokens
How did we find the 20B boundary? Ablation studies. We ran the same compliance evaluation suite across models from 1B to 70B parameters and found a clear inflection point. Below 20B, models consistently struggled with multi-step regulatory reasoning regardless of how much fine-tuning we threw at them. The parameter count was necessary for holding enough context to chain regulatory clauses together.
The tier selection is driven by the consequence of failure, not the volume of traffic. A high-volume FAQ bot belongs in the cost-optimised tier. A low-volume compliance agent belongs in the accuracy-optimised tier.
The Grace Period — Letting the Teacher Teach
When you first deploy an agent, the student has zero knowledge of your application’s behavioral patterns. It has never seen your users, your edge cases, or your domain-specific formatting requirements. It cannot serve production traffic yet.
This is the grace period — the initial phase where 100% of production traffic is routed to the teacher model. Every request-response pair is logged as training data. The teacher is not just serving users — it is generating the curriculum that the student will learn from.
const agentConfig = {
model: {
tier: "accuracy-optimized",
mode: "auto", // platform manages teacher/student transitions
graceperiod: {
minConversations: 300,
minUniqueIntents: 50,
maxDurationDays: 14
}
}
};
The grace period typically spans a few hundred conversations, enough to capture the real distribution of user queries. We found that 300 conversations with at least 50 unique intents gave us sufficient coverage for most fintech use cases. Too short and the student underfits rare but important edge cases. Too long and you are burning teacher-rate tokens without additional benefit.
The grace period is not wasted cost. Every dollar spent on teacher inference during this phase pays for itself many times over in student training quality. You are collecting real production data. Not synthetic benchmarks, not curated examples, but the actual messy, varied, edge-case-filled conversations that your users have. This is what makes the student’s training so effective compared to generic fine-tuning.
The Optimisation Pipeline
Once the grace period collects enough data, the optimisation pipeline kicks in. We designed it as a two-stage process.
Stage 1: Dynamic Prompt Optimisation
Before touching model weights, there is a cheaper optimisation available: prompt engineering at scale. The platform analyses the teacher’s outputs to identify behavioral patterns like common reasoning structures, formatting conventions, domain-specific terminology, and generates specialised system prompts and few-shot examples tailored to the use case.
This is a zero-cost optimisation. No training compute required, just smarter prompting. In our experience, this alone cut costs by 20-30% by allowing a slightly smaller model within the same tier to match teacher quality with better context.
Stage 2: SLM Distillation
The core optimisation. We fine-tune the student model directly on the teacher’s outputs using LoRA (Low-Rank Adaptation), updating only a small number of adapter parameters rather than the entire model. This keeps training fast and cheap while preserving the base model’s general capabilities.
The training data is the set of (input, teacher_output) pairs collected during the grace period. But we are not just training on raw text. We distill the behavioral patterns: the reasoning structure, the tool call sequences, the formatting conventions, the confidence calibration.
distillation_config = {
"base_model": "meta-llama/Llama-3.1-8B-Instruct",
"training_data": "s3://agent-data/fintech-agent/teacher-outputs/",
"method": "lora",
"lora_config": {
"r": 16,
"lora_alpha": 32,
"target_modules": ["q_proj", "v_proj", "k_proj", "o_proj"],
"lora_dropout": 0.05
},
"training_args": {
"num_epochs": 3,
"learning_rate": 2e-4,
"batch_size": 8,
"warmup_ratio": 0.1
},
"validation": {
"holdout_ratio": 0.15,
"quality_threshold": 0.92,
"eval_metrics": ["task_accuracy", "format_compliance", "latency_p95"]
}
}
The quality threshold is critical. The student must achieve 92%+ agreement with the teacher on a held-out validation set before it is allowed anywhere near production traffic. We evaluate on task accuracy (does it get the right answer?), format compliance (does it follow our output schema?), and latency (is it actually faster?).
The Full Lifecycle
Putting it all together, the distillation lifecycle is a five-stage loop, not a one-shot process.
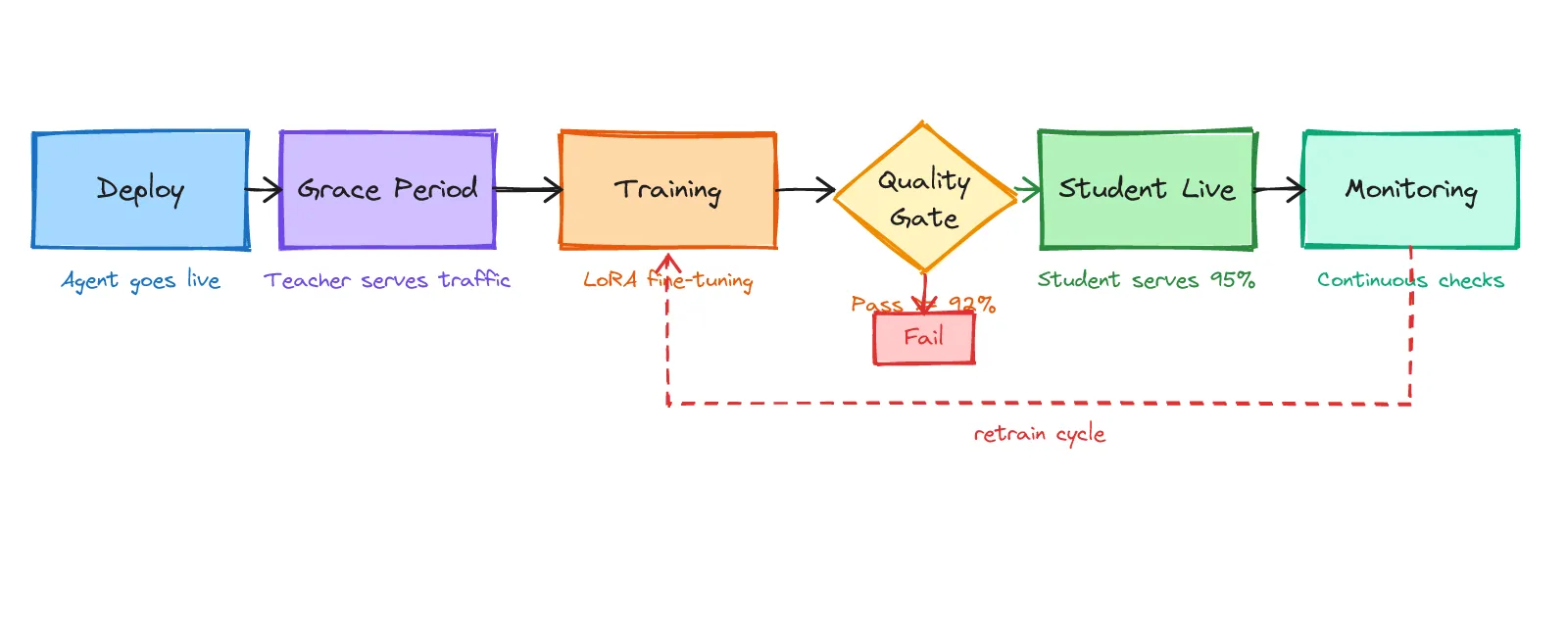
Deploy: The agent goes live. The platform starts in teacher mode.
Grace Period: The teacher handles 100% of production traffic. Every interaction is logged as training data. This phase runs until the minimum conversation and intent thresholds are met.
Training & Validation: The distillation pipeline trains the student on collected data. The student is validated against a held-out set. If it passes the 92% quality gate, it advances. If it fails, the system collects more data and retrains.
Student Live: The student takes over production traffic, typically handling 95% of requests. The remaining 5% are either routed to the teacher (for low-confidence cases) or used as ongoing evaluation samples.
Monitoring: Student outputs are continuously compared against what the teacher would have produced. If quality drifts beyond acceptable thresholds, maybe user behavior shifted or a new regulatory requirement appeared, the system triggers a retrain cycle automatically.
The lifecycle is not one-shot. As user behavior evolves, as regulations change, as the product adds new features, the student needs periodic retraining. The monitoring stage ensures this happens proactively rather than after users start complaining.
Controlling the System
We designed three operational modes for different stages of the development lifecycle:
// During development: always use teacher for highest quality
const devConfig = {
model: { mode: "teacher", tier: "accuracy-optimized" }
};
// In production: let the platform optimise automatically
const prodConfig = {
model: { mode: "auto", tier: "accuracy-optimized" }
};
// Post-optimisation: lock in the cost savings
const costOptConfig = {
model: { mode: "student", tier: "cost-optimized" }
};
Auto mode is the default for production. The platform dynamically manages teacher-to-student transitions: collecting data, training, validating, switching, monitoring. You deploy and let the system optimise itself.
Teacher mode forces every request through the teacher model. We use this during development and QA when we want maximum quality and are willing to pay for it. It is also useful for generating evaluation datasets.
Student mode forces every request through the student. You use this post-optimisation when the student has been validated and you want guaranteed lowest cost with no teacher fallback. We only flip this switch after the student has been stable in auto mode for at least two weeks.
The Results
After running the full lifecycle on our fintech agent, here is what we measured:

Cost: From ~$1.50 per 1M input tokens (teacher) to ~$0.30 per 1M input tokens (student). With 95% of traffic on the student, our monthly bill dropped from $52K to roughly $8K. An ~85% reduction.
Latency: P95 response time went from 3.2 seconds (teacher) to 0.8 seconds (student). The smaller model is fundamentally faster, fewer parameters means fewer compute steps per token. A 4x improvement.
Quality: The student achieved 94% agreement with the teacher on our task-specific evaluation suite. The 6% gap was concentrated in rare edge cases like unusual loan structures and uncommon regulatory intersections that the system automatically routes to the teacher via confidence-based routing.
def route_request(request, student, teacher, confidence_threshold=0.85):
student_response, confidence = student.generate_with_confidence(request)
if confidence >= confidence_threshold:
return student_response # fast, cheap path
# fall back to teacher for low-confidence cases
teacher_response = teacher.generate(request)
log_for_retraining(request, teacher_response) # future training data
return teacher_response
The confidence-based routing is what makes the 94% number acceptable. The student is not silently getting things wrong 6% of the time. It knows when it does not know — and routes those cases to the teacher. Those teacher responses then become training data for the next retraining cycle, gradually closing the gap.
Lessons Learned
Building this system taught us a few things the hard way.
Grace period length matters more than you think. Our first attempt used 100 conversations. The student looked great on common cases but catastrophically failed on a rare regulatory edge case that appeared maybe once per 500 conversations. We bumped the minimum to 300 with an intent diversity requirement. The extra cost during the grace period was nothing compared to the cost of a compliance failure.
Evaluation is harder than training. Building the distillation pipeline took us two weeks. Building a reliable task-specific evaluation suite took us six. Evaluating a model on free-form regulatory analysis is fundamentally harder than training it. We ended up with a hybrid approach: automated metrics for format compliance and citation accuracy, plus weekly human review of a random sample.
Confidence-based routing is essential. Without it, the student is a black box that sometimes fails silently. With it, the student becomes a self-aware system that routes hard cases to the teacher. This single mechanism is what made stakeholders comfortable putting a distilled model in front of compliance-sensitive workflows.
Version your training data and models. We hit a bug in month three where a student model produced slightly different outputs from the same input on different days. Turned out a training data pipeline had a non-deterministic shuffle. We now version everything: training data snapshots, model checkpoints, LoRA adapters, evaluation results, all with full lineage tracking.
Start with prompt optimisation before jumping to fine-tuning. Our first instinct was to go straight to LoRA distillation. A colleague suggested we try prompt optimisation first. It got us 25% of the way there with zero training cost. For simpler use cases, it might be all you need.
When (and When Not) to Build This
This approach makes sense when you have a well-defined, narrow task distribution — your agent does a specific set of things, not everything. When you have high volume — the cost savings compound, and you generate enough training data naturally. When your quality requirements are concrete and measurable — you can define what “good enough” means and evaluate against it.
This approach does NOT make sense when your task distribution is extremely broad (a general-purpose assistant). When your volume is low (the training investment will not pay off). When you need the absolute frontier of capability (novel reasoning, research applications). In those cases, just pay for the frontier model and focus your engineering effort elsewhere.
The future is encouraging. As open-source models improve, the quality gap between teacher and student narrows. The 8B models of today are better than the 70B models of two years ago. The cost savings from distillation will only become more dramatic as base models get more capable.
The key insight is not that small models are good enough. They are not — not out of the box. The insight is that small models, taught by large models on your specific data, can be good enough. The teaching matters more than the size.